首发于知乎:https://zhuanlan.zhihu.com/p/76017554

题目给出了e和n以及密文c,需要求明文m。
解题思路是根据n分解求出p和q,然后根据e,p,q求出d,再根据c,d,n求出明文m。
如何求p和q呢,这里涉及到质因数的分解,linux下一般可直接执行命令factor去分解它:
但是factor能分解的数不是很大,当n特别大的时候可以使用factordb这个命令 :
1
|
factordb 322831561921859
|
使用下面命令来安装factordb:
1
|
pip install factordb-pycli
|
当然,我们也可以直接使用在线网站来分解n:
http://www.factordb.com/index.php
如果n特别大,这个网站也分解不出来,那就算了吧。这个题肯定不是分解n来解题,一定有别的方法。
本题的解题步骤是先求出p和q:

p是13574881或者23781539都行,反正就两个数,你指定第一个是p那么第二个就是q,反之亦可。
解题脚本:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
#!/usr/bin/python
#coding:utf-8
#@Author:Mr.Aur0ra
import libnum
from Crypto.Util.number import long_to_bytes
c = 0xdc2eeeb2782c
n = 322831561921859
e = 23
q = 13574881
p = 23781539
d = libnum.invmod(e, (p - 1) *(q - 1))
m = pow(c, d, n)
print "m的值为:"
print long_to_bytes(m)
|
关于long_to_bytes与bytes_to_long百度一下就知道了,关于如何记住pow里面的变量顺序,我记得好像有个cdn加速来,靠谐音就记住了。关于求d,也就是模逆运算,下面的数学基础中会讲。

题目给出了两个文件,如下图所示:
其中flag.enc是密文,pubkey.pem是公钥。正常的话是必须要有私钥才可以解开密文,但是这里加密的强度不高,所以可以直接解开,下面咱们一起来干点坏事O(∩_∩)O哈!
现在,我们只知道密文c,其他的都不知道,怎么办呢?
这里,我们要读取公钥文件pubkey.pem中的基本信息。
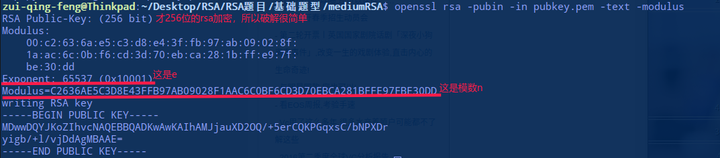
首先把n由16进制转为10进制,接着分解n得到p和q。


现在我们有了n,p,q,e,c。
接着,我们可以根据p,q求phi。然后,再根据phi和e求d。最后,根据c,d,n即可求出明文m。
解题脚本:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
#!/usr/bin/python
#coding:utf-8
#@Author:Mr.Aur0ra
import libnum
from Crypto.Util.number import long_to_bytes
n = 87924348264132406875276140514499937145050893665602592992418171647042491658461
p = 275127860351348928173285174381581152299
q = 319576316814478949870590164193048041239
e = 65537
phi = (p-1)*(q-1)
d = libnum.invmod(e,phi)
with open('./flag.enc') as f:
c = f.read().encode('hex')
c = int(c,16)
m = pow(c,d,n)
print long_to_bytes(m)
|
或者
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
#!/usr/bin/python
#coding:utf-8
#@Author:Mr.Aur0ra
import gmpy2
from Crypto.Util.number import long_to_bytes
n = 87924348264132406875276140514499937145050893665602592992418171647042491658461
p = 275127860351348928173285174381581152299
q = 319576316814478949870590164193048041239
e = 65537
phi = (p-1)*(q-1)
d = gmpy2.invert(e,phi)
with open('./flag.enc') as f:
c = f.read().encode('hex')
c = int(c,16)
m = pow(c,d,n)
print long_to_bytes(m)
|

关于文件形式的密文c,一般都是16进制形式读取,接着再转为整型用于计算。上面的读取代码有点冗余了,后面的题目会有更简洁的读取方式。
真的忘了题目是哪个比赛的题,就叫存货吧。
题目:
1
2
3
4
5
|
p+q : 0x1232fecb92adead91613e7d9ae5e36fe6bb765317d6ed38ad890b4073539a6231a6620584cea5730b5af83a3e80cf30141282c97be4400e33307573af6b25e2ea
(p+1)(q+1) : 0x5248becef1d925d45705a7302700d6a0ffe5877fddf9451a9c1181c4d82365806085fd86fbaab08b6fc66a967b2566d743c626547203b34ea3fdb1bc06dd3bb765fd8b919e3bd2cb15bc175c9498f9d9a0e216c2dde64d81255fa4c05a1ee619fc1fc505285a239e7bc655ec6605d9693078b800ee80931a7a0c84f33c851740
e : 0xe6b1bee47bd63f615c7d0a43c529d219
d : 0x2dde7fbaed477f6d62838d55b0d0964868cf6efb2c282a5f13e6008ce7317a24cb57aec49ef0d738919f47cdcd9677cd52ac2293ec5938aa198f962678b5cd0da344453f521a69b2ac03647cdd8339f4e38cec452d54e60698833d67f9315c02ddaa4c79ebaa902c605d7bda32ce970541b2d9a17d62b52df813b2fb0c5ab1a5
enc_flag: 0x50ae00623211ba6089ddfae21e204ab616f6c9d294e913550af3d66e85d0c0693ed53ed55c46d8cca1d7c2ad44839030df26b70f22a8567171a759b76fe5f07b3c5a6ec89117ed0a36c0950956b9cde880c575737f779143f921d745ac3bb0e379c05d9a3cc6bf0bea8aa91e4d5e752c7eb46b2e023edbc07d24a7c460a34a9a
|
题目给出了p+q,(p+1)(q+1),e,d,c。
当时做这题的时候就蒙了,n在哪? p,q呢? 我是谁? 我在哪? 仔细想了一会,掏出笔记本列了一下等式关系,就出来了…
1
2
3
4
5
6
7
|
(p+1)(q+1)
= p*q + p + q + 1
= n + (p+q) + 1
那么:
n = (p+1)(q+1) - (p+q) - 1
m = pow(c,d,n)
|
解题脚本:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
#!/usr/bin/python
#coding:utf-8
#@Author:Mr.Aur0ra
import gmpy2
from Crypto.Util.number import long_to_bytes
#p+q用x表示
#(p+1)(q+1)用y表示
x = 0x1232fecb92adead91613e7d9ae5e36fe6bb765317d6ed38ad890b4073539a6231a6620584cea5730b5af83a3e80cf30141282c97be4400e33307573af6b25e2ea
y = 0x5248becef1d925d45705a7302700d6a0ffe5877fddf9451a9c1181c4d82365806085fd86fbaab08b6fc66a967b2566d743c626547203b34ea3fdb1bc06dd3bb765fd8b919e3bd2cb15bc175c9498f9d9a0e216c2dde64d81255fa4c05a1ee619fc1fc505285a239e7bc655ec6605d9693078b800ee80931a7a0c84f33c851740
d = 0x2dde7fbaed477f6d62838d55b0d0964868cf6efb2c282a5f13e6008ce7317a24cb57aec49ef0d738919f47cdcd9677cd52ac2293ec5938aa198f962678b5cd0da344453f521a69b2ac03647cdd8339f4e38cec452d54e60698833d67f9315c02ddaa4c79ebaa902c605d7bda32ce970541b2d9a17d62b52df813b2fb0c5ab1a5
c = 0x50ae00623211ba6089ddfae21e204ab616f6c9d294e913550af3d66e85d0c0693ed53ed55c46d8cca1d7c2ad44839030df26b70f22a8567171a759b76fe5f07b3c5a6ec89117ed0a36c0950956b9cde880c575737f779143f921d745ac3bb0e379c05d9a3cc6bf0bea8aa91e4d5e752c7eb46b2e023edbc07d24a7c460a34a9a
n = y - x - 1
m = pow(c,d,n)
print long_to_bytes(m)
|
其实这个题也不是很难哈,就是替换一下什么的的数学小游戏罢了。真正难的在最后面。
感谢评论区的大佬 @Tiger 1218 给了它个名分。该题目取自GUET-CTF 2019中的BabyRSA。
这部分是我从别人那里搬来的,然后做了一点点的修改,我觉得吧,还是应该看些数学原理的。毕竟越往深了学,用到的数学知识就越多。话说数学好的人是真的优秀,作为学习网络工程的人,在我眼里,香农是通信方面的大佬,令我没想到的是,他还是个数学专家和密码学专家,业余无聊搞一搞通信。这人太狠了。
如果实在看不懂可以跳过这部分,进入下个标题的学习。不要看都没看就跳过哈。哪怕稍微看点再看下一篇也行。
下面的知识参考链接:
CTF中常见的RSA相关问题总结[转]:willv.cn/2018/07/21/RSA-ATTACK/
上面讲的公钥和私钥产生多半是大白话的,下面是偏数学上的介绍,也很好理解啦:
(1)选取两个较大的互不相等的质数p和q。计算n = p * q。n用于定义模运算的范围。
(2)计算φ(n) = (p-1) * (q-1)。φ(n)是欧拉函数值,在编程时也常用phi表示。
(3)选取一个整数e,使得e满足 1 < e < φ(n) 且 gcd(e , φ(n)) == 1。这里的gcd表示最大公约数,也就是说e和φ(n)是互质的。
(4)计算e关于φ(n)的模逆元d, 即找到一个整数d满足 (e * d) % φ(n) == 1。
(5)加密过程:给定明文m,计算密文c = (m ^ e) % n。
(6)解密过程:给定密文c,计算明文m = (c ^ d) % n。
其中,m为明文,c为密文,(n,e)为公钥对,d为私钥。
如果(a*b)%c==1 ,那么a和b互为对方模c的模逆元/数论倒数,也写作mod_inv 。

关于最大公约数有一个基本事实:给予两整数a、c,必存在整数x、y使得ax + cy = gcd(a,c) ,基于这个事实,当a,c互素即gcd(a,c)==1时,有ax+cy=1 ,那么就有(a*x)%c==1 ,所以x就是a 对c的模逆元。因此,a对c存在模逆元b的充要条件是gcd(a,c)==1 。显然对于每一组a,c ,存在一族满足条件的x,在求模逆元时我们取得是最小正整数解x mod n 。
上述的基本事实很容易理解,因为a和c的最大公约数是gcd(a,b),所以a和c都可表示为gcd(a,b)的整数倍,那么a和b的任意整系数的线性组合ax+by也必定能表示成gcd(a,c)的整数倍,他们当中最小的正整数就应该是gcd(a,c)。实际上最大公约数有一个定义就是:a和b的最大公约数g是a和b的线性和中的最小正整数 。
求模逆元主要基于扩展欧几里得算法,贴一个Python实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
#!/usr/bin/python
#coding:utf-8
#47模30的逆为23
def egcd ( a , b ):
if (b == 0):
return 1, 0, a
else:
x , y , q = egcd( b , a % b ) # q = GCD(a, b) = GCD(b, a%b)
x , y = y, ( x - (a // b) * y )
return x, y, q
def mod_inv(a,b):
#return egcd(a,b)[0]%b #求a模b得逆元
print egcd(a,b)[0]%b
def main():
a = 47
b = 30
mod_inv(a,b)
if __name__=="__main__":
main()
|
或者(推荐)
1
2
3
4
5
6
7
8
|
#!/usr/bin/python
#coding:utf-8
#@Author:Mr.Aur0ra
#求47模30的逆为23
import gmpy2
print gmpy2.invert(47,30)
|
熟悉吧,前面求d的时候用的就是这个。
3. 模意义下的运算法则
(a + b) % n ≡ (a % n + b % n) % n
(a - b) % n ≡ (a % n - b % n) % n
(a * b) % n ≡ (a % n * b % n) % n
(a ^ b) % n ≡ ((a % n) ^ b) % n //幂运算
若 a ≡ b(mod n) ,则
(1)对于任意正整数c,有a^c ≡ b^c(mod n)
(2)对于任意整数c,有ac ≡ bc(mod n),a+c ≡ b+c(mod n),
(3)若 c ≡ d(mod n),则a-c ≡ b-d(mod n),a+c ≡ b+d(mod n),ac ≡ bd(mod n)
如果ac≡bc (mod m),且c和m互质,则a≡b (mod m)[理解:当且仅当c和m互质,c^-1存在,等式左右可同乘模逆。]
除法规则:
在模n意义下,a/b不再仅仅代表这两个数相除,而是指a+k1*n和b+k2*n这两个组数中任意两个相除,使商为整数。
因此也就可以理解,除以一个数等价于乘以它的逆
a/b ≡ c(mod n) <=> a ≡ c*(b^-1) (mod n),其中b模n的逆记作b的负一次方。
a是整数,p是质数,则a^p==a(mod p),如果a不是p的倍数,还有a^(p-1) ≡ 1(mod p)
欧几里得算法是求最大公约数的算法, 也就是中学学的 辗转相除法。记 gcd(a,b)为a和b的最大公约数。
欧几里得算法的基本原理是gcd(a,b)==gcd(b,a%b),(b!=0) 和 gcd(a,0)==a 。
1
2
3
4
5
6
7
8
|
# 递归版
def gcd(a, b):
return a if not b else gcd(b, a % b)
# 迭代版
def gcd2(a, b):
while b:
a, b = b, a % b
return a
|
扩展欧几里得算法基于欧几里得算法,能够求出使得ax+by=gcd(a,b)的一组x,y。
对照下图和以下递归版实现容易理解。

python实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
# 递归版
def ext_euclid ( a , b ):
# ref:https://zh.wikipedia.org/wiki/扩展欧几里得算法
if (b == 0):
return 1, 0, a
else:
x1 , y1 , q = ext_euclid( b , a % b ) # q = GCD(a, b) = GCD(b, a%b)
x , y = y1, ( x1 - (a // b) * y1 )
return x, y, q
# 迭代版
def egcd(a, b):
# ref:https://blog.csdn.net/wyf12138/article/details/60476773
if b == 0:
return (1, 0, a)
x, y = 0, 1
s1, s2 = 1, 0
r, q = a % b, a / b
while r:
m, n = x, y
x = s1 - x * q
y = s2 - y * q
s1, s2 = m, n
a, b = b, r
r, q = a % b, a / b
return (x, y, b)
|
7. 中国剩余定理

python实现如下:
1
2
3
4
5
6
7
8
9
10
11
|
def CRT(mi, ai):
# mi,ai分别表示模数和取模后的值,都为列表结构
# Chinese Remainder Theorem
# lcm=lambda x , y:x*y/gcd(x,y)
# mul=lambda x , y:x*y
# assert(reduce(mul,mi)==reduce(lcm,mi))
# 以上可用于保证mi两两互质
assert (isinstance(mi, list) and isinstance(ai, list))
M = reduce(lambda x, y: x * y, mi)
ai_ti_Mi = [a * (M / m) * gmpy2.invert(M / m, m) for (m, a) in zip(mi, ai)]
return reduce(lambda x, y: x + y, ai_ti_Mi) % M
|
以上程序将mi当作两两互质处理,实际上有时会遇到其他情况,这时就需要逐一两两合并方程组。我(不是我)参照下图实现了一个互质与不互质两种情况下都能工作良好的中国剩余定理(解同余方程组)的Python程序。
1
2
3
4
5
6
7
8
9
10
11
12
13
|
def GCRT(mi, ai):
# mi,ai分别表示模数和取模后的值,都为列表结构
assert (isinstance(mi, list) and isinstance(ai, list))
curm, cura = mi[0], ai[0]
for (m, a) in zip(mi[1:], ai[1:]):
d = gmpy2.gcd(curm, m)
c = a - cura
assert (c % d == 0) #不成立则不存在解
K = c / d * gmpy2.invert(curm / d, m / d)
cura += curm * K
curm = curm * m / d
cura %= curm
return (cura % curm, curm) #(解,最小公倍数)
|

好了,如果都看到这里了的话,说明你还是很厉害的,给你点个赞。